
31·
3 days agoI lost it when coming across this commit: https://github.com/WinampDesktop/winamp/commit/67c68e6dc24f36b266427034d016fb86ef4d486c
I lost it when coming across this commit: https://github.com/WinampDesktop/winamp/commit/67c68e6dc24f36b266427034d016fb86ef4d486c

Other commenters addressed some of the possible clearance issues, where a wider tire might interfere with the frame. But it seems to me that the discussion on tire/rim compatibility can be fleshed out.
To lay some background, a bicycle tire is essentially mostly a hollow rubber donut, but with the inward-facing “donut hole” walls supported instead by a pair of co-axial steel hoops, known as the beads. Thus, the beads define the inner diameter of the tire. When a tire is inflated, the air pressure will cause expansion in all directions. The tire’s beads and walls (ie casing) will hold their shape, but the air pressure will try to push the two beads apart. This is where the rim walls come into play: the rim walls prevent the beads from widening apart. With the air pressure fully contained in all directions, the wheel assembly can now support impressive loads relative to the weight of the rubber and metal.

So for a bicycle rim and bicycle tire to be compatible, the two most basic criteria must be met:
The first criteria is a strict match, so that’s easy to check. But the second criteria has some allowance for different tire widths on a given rim, or different rims for a given tire width. We can now look at what rims you have, and whether they’re compatible with your preferred tires.
It looks like your rims are Weinmann DP18 rims, which have a trade diameter of 700C and the narrowest part of the rim walls are 12.40 mm apart. I say “trade diameter” because no part of the rim actually measures 700 mm. Instead, rim/tire compatibility can only reliably be calculated using the ISO/ETRTO measurements, which are a pair of numbers that directly answer the two compatibility criteria from earlier.
The first number in the ETRTO system is the inner rim width, and the second number is the bead seat diameter, both in millimeters. So your rims would be universally identified as 12-622 or 13-622, since 622 mm is the actual circumference if you put a tape measure around the rim. The first number can be 12 or 13 because 12.40 mm could round up or down. Sub-mm precision does not substantially matter here.
Now we can look at your desired tires, which have a trade designation of 700x38c but they also give the ETRTO measurement of 40-622. Unlike rims, the trade designation does actually convey some measurable dimension of the tire, but these are irrelevant for tire/rim compatibility. See the spoiler below for more.
In this case, 700 mm is the approximate outer diameter of the tire, which is only useful if:
Also, 38 mm is the approximate width of the tire when inflated. This is allowed to differ from the ETRTO width, since balloon tires on MTB bikes can be substantially wider than the rim, and road bike tires can be narrower than the rim. This width is mostly only useful to check the clearance between your forks, although it’s also useful to know if you’re riding near streetcar tracks.
Narrow tires can get caught in the groove along the tracks, whereas wider tires can glide over them. A skilled rider can navigate tracks with any tire width, but it’s still a hazard that needs to be identified and negotiated.
So we now know the rim is 13-622 and the desired tire is 40-622. Checking the first criteria, we see that the diameters (622 mm) are a perfect match. Great! But for the width, because there is an allowable range, we need to consult a width compatibility table. Some tire manufacturers will be more permissive while others are more conservative with their published tables. And there are often separate tables for road bikes versus MTB. But these tables won’t vary too substantially in their recommendations. Here are two tables, one from Continental and another from WTB.


Both tables indicate that for the 13 mm rim width column, the recommended tire widths are 18-27 mm (Continental) or 23-25 mm (WTB). Your preferred tire has an ETRTO width of 40 mm, which is way too far outside of the recommendations. So no, it doesn’t look like this tire can be safely mounted on your existing rims.
But what would happen if you tried it anyway? We can see from the table that a 40 mm tire should normally be mounted on a rim with widths 17-27 mm. So 13 mm would mean the tire beads will be squeezed closer together than designed. This means more of the tire’s tread will be wrapped up on the sides rather than facing down at the road. This also reduces the contact patch where the tire meets the road.
Finally, a wide tire on a narrow rim exerts more leverage that could pull the tire up and off the rim. This would happen if the bike is loaded sideways, such as leaning the bike to one side while riding straight, or when the rider leans further than the bike in a curve. The recommended values take these conditions into account, so exceeding the recommendations might still work day-to-day but fail during rarer conditions.
My recommendation is to pursue a new set of rims that can support tire widths suitable for your new environment. As the tables show, 13 mm rims are very limiting, but 17 mm rims are very permissive. Indeed, a 17 mm rim would actually allow you to mount your preferred tires (ETRTO 40-622) and possibly your existing tires (ETRTO 25-622 ?) too, if you wanted to.
I wish you good luck in your endeavors!
This reminds me of the time I happened to be at a warehouse where an industrial motor control panel was being decommissioned. In the center of the panel is a large breaker, which was dutifully opened (ie powered off) before work commenced. But bizarrely, someone in the past managed to tap power from the supply-side of the breaker for some sort of monitoring sensor inside the panel. So when that circuit was cut through, there was a loud bang and the overhead lights went out.
No one was injured, although everyone was jumpy from the inadvertent light-and-sound spectacle. And a set of cutters gained a 12 AWG-sized (approx 4 mm^2) hole.
I may have misremembered some details, but my takeaway as a non-electrician was to 1) never assume a breaker handle at face value, and 2) don’t assume the prior person made sane choices.
This is a good question and I don’t really know how this device would affect drafting and related manoeuvres. But if I had to guess, drafting behind a lead cyclist should still be beneficial, but the “zones” where it works might change.
So for example, the optimal distance lee-ward of a lead cyclist might become shorter or longer. Longer could mean more space to vie for that position directly behind the lead. But shorter might mean it’s impossible to draft without crashing into the lead.
Side-to-side drafting distances might also be affected, like how birds travel in a vee-shape. Maybe the vee would become wider? That might not be beneficial, though, if it’s so wide that it’s impossible to stay on the racecourse.
TL;DR: I have no idea, and aerodynamics are hard. That’s why I’m intrigued by the field.
My understanding is that it has to do with form drag – aka pressure drag – which results in vortices forming in the “separation region” directly behind an airfoil. Or in this case, a rider. Essentially, the swirling of air behind the rider is turbulent – which is why a hoodie might flop all over the place – and that causes energy to be lost.
This video on Nebula (and YT as well) describes pressure drag at about the 02m30s mark for a sphere. But this graphic from Skybrary also shows the problem:
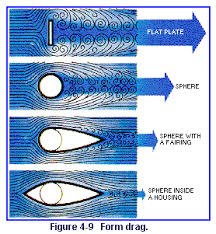
By providing a smooth surface for air to “cling” to, where it would otherwise form vortices in the separation region, should reduce form drag, although it will cause additional induced drag (aka friction with the new surface). But induced drag scales with speed and at cycling speeds, that’s less a problem than it would be at airplane speeds.
A related drag-reducing device has been used for semi-truck trailers, and those have really been proven to reduce fuel consumption. Although the Wikipedia article does not describe in detail the aerodynamic principles at play.

For reference, the current Flag of Milwaukee, WI, which is quite busy:

As for the so-called “People’s Flag” – either with or without the city hall barreling into the harbor – it bears a small resemblance to the flag of Reno, NV, which is a pleasing flag.
Robert Lenz’s “Sunrise Over the Lake”, selected after a public competition, which prompted the humorous version with the city hall building.

The thing to keep in mind is that there exist things which have “circumstantial value”, meaning that the usefulness of something depends on the beholder’s circumstances at some point in time. Such an object can actually have multiple valuations, as compared to goods (which have a single, calculable market value) or sentimental objects (“priceless” to their owner).
To use an easy example, consider a sportsball ticket. Presenting it at the ballfield is redeemable for a seat to watch the game at the time and place written on the ticket. And it can be transferred – despite Ticketmaster’s best efforts – so someone else could enjoy the same. But if the ticket is unused and the game is over, then the ticket is now worthless. Or if the ticket holder doesn’t enjoy watching sportsball, their valuation of the ticket is near nil.
So to start, the coupon book is arguable “worth” $30, $0, or somewhere in between. Not everyone will use every coupon in the book. But if using just one coupon will result in a savings of at least $1, then perhaps the holder would see net-value from that deal. In no circumstance is KFC marking down $30 on their books because they issued coupons that somehow total to $30.
That said, I’m of the opinion that if a donation directly results in me receiving something in return… that’s not a donation. It’s a sale or transaction dressed in the clothes of charity. Plus, KFC sends coupons in the mail for free anyway.
Notwithstanding the possible typo in the title, I think the question is why USA employers would prefer to offer a pension over a 401k, or vice-versa.
For reference, a pension is also known as a defined benefit plan, since an individual has paid into the plan for the minimum amount will be entitled to some known amount of benefit, usually in the form of a fixed stipend for the remainder of their life, and sometimes also health insurance coverage. USA’s Social Security system is also sometimes called the public pension, because it does in-fact pay a stipend in old age and requires a certain amount of payments into the fund during one’s working years.
Whereas a 401k is uncreatively named after the tax code section which authorized its existence, initially being a deferred compensation mechanism – aka a way to spread one’s income over more time, to reduce the personal taxes owed in a given year – and then grew into the tax-advantaged defined contribution plan that it is today. That is, it is a vessel for saving money, encouraged by tax advantages and by employer contributions, if any.
The superficial view is that 401k plans overtook pensions because companies wouldn’t have to contribute much (or anything at all), shifting retirement costs entirely onto workers. But this is ahistorical since initial 401k plans offered extremely generous employer contribution rates, some approaching 15% matching. Of course, the reasoning then was that the tax savings for the company would exceed that, and so it was a way to increase compensation for top talent. In the 80s and 90s was when the 401k was only just taking hold as a fringe benefit, so you had to have a fairly cushy job to have access to a 401k plan.
Another popular viewpoint is that workers prefer 401k plans because it’s more easily inspectable than a massive pension fund, and history has shown how pension funds can be mismanaged into non-existence. This is somewhat true, if US States’ teacher pension funds are any indication, although Ontario Teacher’s Pension Plan would be the counterpoint. Also, the 401k plan participants at Enron would have something to complain about, as most of the workers funds were invested in the company itself, delivering a double whammy: no job, and no retirement fund.
So to answer the question directly, it is my opinion that the explosion of 401k plans and participants in such plans – to the point that some US states are enacting automatic 401k plans for workers whose employers don’t offer one – is due to 1) momentum, since more and more employers keep offering them, 2) but more importantly, because brokers and exchanges love managing them.
This is the crux: only employers can legally operate a 401k plan for their employees to participate in. But unless the employer is already a stock trading platform, they are usually ill-equiped to set up an integrated platform that allows workers to choose from a menu of investments which meet the guidelines from the US DOL, plus all other manner of regulatory requirements. Instead, even the largest employers will partner with a financial services company who has expertise on offering a 401k plan, such as Vanguard, Fidelity, Merrill Edge, etc.
Naturally, they’ll take a cut on every trade or somehow get compensated, but because of the volume of 401k investments – most people auto-invest every paycheck – even small percentages add up quickly. And so, just like the explosion of retail investment where ordinary people could try their hand at day-trading, it’s no surprise that brokerages would want to extend their hand to the high volume business of operating 401k plans.
Whereas, how would they make money off a pension fund? Pension funds are multi-billion dollar funds, so they can afford their own brokers to directly buy a whole company in one-shot, with no repeat business.
Almost. By virtue of being a smaller antenna, the 30 cm panel does not focus its energy as tightly as a larger (eg 60 cm) antenna. Likewise, a smaller antenna does not pick up (ie receive) as much energy as a larger antenna does. Thus, by using a 30 cm panel, less of the high energy from the opposite radio will reach the receiver, and that keeps the receiver from being damaged.
In RF engineering, there is a careful balance between output power, antenna size/shape, environmental conditions, and desired link quality. Whoever built the radio link originally did not apparently perform the necessary calculation. I’m not an RF engineer, but for spanning a mere 50 meters, this 20 cm antenna with built-in radio should be more than sufficient for a basic link.
Normally, increased RF power is helpful to overcome interference or noise. Just like how normally, an automobile or airplane will be easier to operate if it has a bigger engine with more power.
At some point, though, the extra RF or engine power is no longer beneficial but also isn’t harmful. And if you go significantly beyond that, then you end up in a region where the extra power is downright harmful and is actively working against you.
Consider an automobile driving in a rainstorm. Having more power is bad, because the tires can lose grip more easily, leading to a crash. In an airplane that has gotten into a stall, applying power is the wrong solution and just aggravates the stall, which is not good.
Here, adding more RF power is just cooking the other receiver like it’s a Thanksgiving turkey. The extra power is no longer helpful for making communications, and may be physically damaging the receiver.
Although copyright and patents (and trademarks) are lumped together as “intellectual property”, there’s almost nothing which is broadly applicable to them all, and they might as well be considered separately. The only things I can think of – and I’m not a lawyer of any kind – are that: 1) IP protection is mentioned vaguely in the US Constitution, and 2) they all behave as property, in that they can be traded/reassigned. That’s it.
With that out of the way, it’s important to keep in mind that patent rights are probably the strongest in the family of IP, since there’s no equivalent “fair use” (US) or “fair dealing” (UK) allowance that copyright has. A patent is almost like owning an idea, whereas copyright is akin to owning a certain rendition plus a derivative right.
Disney has leaned on copyright to carve for themselves an exclusive market of Disney characters, while also occasionally renewing their older characters (aka derivatives), so that’s why they lobby for longer copyright terms.
Whereas there isn’t really a singular behemoth company whose bread-and-butter business is to churn out patents. Inventing stuff is hard, and so the lack of such a major player means a lack of lobbying to extend patent terms.
To be clear, there are companies who rely almost entirely on patent law for their existence, just like Disney relies on copyright law. But type foundries (companies that make fonts) are just plainly different than Disney. Typefaces (aka fonts) as a design can be granted patents, and then the font files can be granted copyright. But this is a special case, I think.
The point is: no one’s really clamoring for longer parents, and most people would regard a longer exclusive term on “ideas” to be very problematic. Esp if it meant pharmaceutical companies could engage in even more price-gouging, for example.
The original tech installed a 60cm panel for a rf link which is no more than 50M.
In case anyone else has this minor confusion, this is a radio link between two buildings which are 50 meters apart. And a square, directional flat-panel antenna that is 60 centimeters on a side is grossly overkill for the short distance involved.

To be clear, the legs would support the topper when it’s positioned over the tub, and also support the topper when it’s beside the tub? If that’s the case, do the legs really need to fold away? Would fixed legs be acceptable? Or is there a requirement that the legs be foldable to provide clearance over the edge of the tub?
If you hold a patent, then you have an exclusive right to that invention for a fixed period, which would be 20 years from the filing date in the USA. That would mean Ford could not claim the same or a derivative invention, at least not for the parts which overlap with your patent. So yes, you could sit on your patent and do nothing until it expires, with some caveats.
But as a practical matter, the necessary background research, the application itself, and the defense of a patent just to sit on it would be very expensive, with no apparent revenue stream to pay for it. I haven’t looked up what sort of patent Ford obtained (or maybe they’ve merely started the application) but patents are very long and technical, requiring whole teams of lawyers to draft properly.
For their patent to be valid, they must not overlap with an existing claim, as well as being novel and non-obvious, among other requirements. They would only file a patent to: 1) protect themselves from competition in future, 2) expect that this patent can be monetized by directly implementing it, or licensing it out to others, or becoming a patent troll and extracting nuisance-value settlements, or 3) because they’re already so deep in the Intellectual Property land-grab that they must continue to participate by obtaining outlandish patents. The latter is a form of “publish or perish” and allows them to appear like they’re on the cutting edge of innovation.
A patent can become invalidated if it is not sufficiently defended. This means that if no one even attempts to infringe, then your patent would be fine. But if someone does, then you must file suit or negotiate a license with them, or else they can challenge the validity of your patent. If they win, you’ll lose your exclusive rights and they can implement the invention after all. This is not cheap, and Ford has deep pockets.
I’ll address your question in two parts: 1) is it redundant to store both the IP subnet and its subnet mask, and 2) why doesn’t the router store only the bits necessary to make the routing decision.
Prior to the introduction of CIDR – which came with the “slash” notation, like /8 for the 10.0.0.0 RFC1918 private IPv4 subnet range – subnets would genuinely be any bit arrangement imaginable. The most sensible would be to have contiguous MSBit-justified subnet masks, such as 255.0.0.0. But the standard did not preclude using something unconventional like 255.0.0.1.
For those confused what a 255.0.0.1 subnet mask would do – and to be clear, a lot of software might prove unable to handle this – this is describing a subnet with 2^23 addresses, where the LSBit must match the IP subnet. So if your IP subnet was 10.0.0.0, then only even numbered addresses are part of that subnet. And if the IP subnet is 10.0.0.1, then that only covers odd numbered addresses.
Yes, that means two machines with addresses 10.69.3.3 and 10.69.3.4 aren’t on the same subnet. This would not be allowed when using CIDR, as contiguous set bits are required with CIDR.
So in answer to the first question, CIDR imposed a stricter (and sensible) limit on valid IP subnet/mask combinations, so if CIDR cannot be assumed, then it would be required to store both of the IP subnet and the subnet mask, since mask bits might not be contiguous.
For all modern hardware in the last 15-20 years, CIDR subnets are basically assumed. So this is really a non-issue.
For the second question, the router does in-fact store only the necessary bits to match the routing table entry, at least for hardware appliances. Routers use what’s known as a TCAM memory for routing tables, where the bitwise AND operation can be performed, but with a twist.
Suppose we’re storing a route for 10.0.42.0/24. The subnet size indicates that the first 24 bits must match a prospective destination IP address. And the remaining 8 bits don’t matter. TCAMs can store 1’s and 0’s, but also X’s (aka “don’t cares”) which means those bits don’t have to match. So in this case, the TCAM entry will mirror the route’s first 24 bits, then populate the rest with X’s. And this will precisely match the intended route.
As a practical matter then, the TCAM must still be as wide as the longest possible route, which is 32 bits for IPv4 and 128 bits for IPv6. Yes, I suppose some savings could be made if a CIDR-only TCAM could conserve the X bits, but this makes little difference in practice and it’s generally easier to design the TCAM for max width anyway, even though non-CIDR isn’t supported on most routing hardware anymore.
To start off, I’m sorry to hear that you’re not receiving the healthcare you need. I recognize that these words on a screen aren’t going to solve any concrete problems, but in the interest of a fuller comprehension of the USA healthcare system, I will try to offer an answer/opinion to your question that goes into further depth than simply “capitalism” or “money and profit” or “greed”.
What are my qualifications? Absolutely none, whatsoever. Although I did previously write a well-received answer in this community about the USA health insurance system, which may provide some background for what follows.
In short, the USA healthcare system is a hodge-podge of disparate insurers and government entities (collectively “payers”), and doctors, hospitals, clinics, ambulances, and more government entities (collectively “providers”) overseen by separate authorities in each of the 50 US States, territories, tribes, and certain federal departments (collectively “regulators”). There is virtually no national-scale vertical integration in any sense, meaning that no single or large entity has the viewpoint necessary to thoroughly review the systemic issues in this “system”, nor is there the visionary leadership from within the system to even begin addressing its problems.
It is my opinion that by bolting-on short-term solutions without a solid long-term basis, the nation was slowly led to the present dysfunction, akin to boiling a frog. And this need not be through malice or incompetence, since it can be shown that even the most well-intentioned entities in this sordid and intricate pantomime cannot overcome the pressures which this system creates. Even when there are apparent winners like filthy-rich plastic surgeons or research hospitals brimming with talented expert doctors of their specialty, know that the toll they paid was heavy and worse than it had to be.
That’s not to say you should have pity on all such players in this machine. Rather, I wish to point to what I’ll call “procedural ossification”, as my field of computer science has a term known as “protocol ossification” that originally borrowed the term from orthopedia, or the study of bone deformities. How very fitting for this discussion.
I define procedural ossification as the loss of flexibility in some existing process, such that rather than performing the process in pursuit of a larger goal, the process itself becomes the goal, a mindless, rote machine where the crank is turned and the results come out, even though this wasn’t what was idealized. To some, this will harken to bureaucracy in government, where pushing papers and forms may seem more important that actually solving real, pressing issues.
I posit to you that the USA healthcare system suffers from procedural ossification, as many/most of the players have no choice but to participate as cogs in the machine, and that we’ve now entirely missed the intended goal of providing for the health of people. To be an altruistic player is to be penalized by the crushing weight of practicalities.
What do I base this on? If we look at a simple doctor’s office, maybe somewhere in middle America, we might find the staff composed of a lead doctor – it’s her private practice, after all – some Registered Nurses, administrative staff, a technician, and an office manager. Each of these people have particular tasks to make just this single doctor’s office work. Whether it’s supervising the medical operations (the doctor) or operating/maintaining the X-ray machine (technician) or cutting the checks to pay the building rent (office manager), you do need all these roles to make a functioning, small doctor’s office.
How is this organization funded? In my prior comment about USA health insurance, there was a slide which showed the convoluted money flows from payers to providers, which I’ve included below. What’s missing from this picture is how even with huge injections of money, bad process will lead to bad outcomes.
In an ideal doctor’s office, every patient that walks in would be treated so that their health issues are managed properly, whether that’s fully curing the condition or controlling it to not get any worse. Payment would be conditioned upon the treatment being successful and within standard variances for the cost of such treatment, such as covering all tests to rule out contributing factors, repeat visits to reassess the patient’s condition, and outside collaboration with other doctors to devise a thorough plan.
That’s the ideal, and what we have in the USA is an ossified version of that, horribly contorted and in need of help. Everything done in a doctor’s office is tracked with a “CPT/HCPCS code”, which identifies the type of service rendered. That, in and of itself, could be compatible with the ideal doctor’s office, but the reality is that the codes control payment as hard rules, not considering “reasonable variances” that may have arisen. When you have whole professions dedicated to properly “coding” procedures so an insurer or Medicare will pay reimbursement, that’s when we’ve entirely lost the point and grossly departed from the ideal. The payment tail wags the doctor dog.
To be clear, the coding system is well intentioned. It’s just that its use has been institutionalized into only ever paying out if and only if a specific service was rendered, with zero consideration for whether this actually advanced the patient’s treatment. The coding system provides a wealth of directly-comparable statistical data, if we wanted to use that data to help reform the system. But that hasn’t substantially happened, and when you have fee-for-service (FFS) as the base assumption, of course patient care drops down the priority list. Truly, the acronym is very fitting.
Even if the lead doctor at this hypothetical office wanted to place patient health at the absolute forefront of her practice, she will be without the necessary tools to properly diagnose and treat the patient, if she cannot immediately or later obtain reimbursement for the necessary services rendered. She and her practice would have to absorb costs that a “conforming” doctor’s office would not have, and that puts her at a further disadvantage. She may even run out of money and have to close.
The only major profession that I’m immediately aware of which undertakes unknown costs with regularity, in the hopes of a later full-and-worthwhile reimbursement, is the legal profession. There, it is the norm for personal injury lawyers to take cases on contingency, meaning that the lawyer will eat all the costs if the lawsuit does not ultimately prevail. But if the lawyer succeeds, then they earn a fixed percentage of the settlement or court judgement, typically 15-22%, to compensate for the risk of taking the case on contingency.
What’s particularly notable is that lawyers must have a good eye to only accept cases they can reasonably win, and to decline cases which are marginal or unlikely to cover costs. This heuristic takes time to hone, but a lawyer could start by being conservative with cases accepted. The reason I mention this is because a doctor-patient relationship is not at all as transactional as a lawyer-client relationship. A doctor should not drop a patient because their health issues won’t allow the doctor to recoup costs.
The notion that an altruistic doctor’s office can exist sustainably under the FFS model would require said doctor to discard the final shred of decency that we still have in this dysfunctional system. This is wrong in a laissez-faire viewpoint, wrong in a moral viewpoint, and wrong in a healthcare viewpoint. Everything about this is wrong.
But the most insidious problems are those that perpetuate themselves. And because of all those aforementioned payers, providers, and regulators are merely existing and cannot themselves take the initiative to unwind this mess, it’s going to take more than a nudge from outside to make actual changes.
As I concluded my prior answer on USA health insurance, I noted that Congressional or state-level legislation would be necessary to deal with spiraling costs for healthcare. I believe the same would be required to refocus the nation’s healthcare procedures to put patient care back as the primary objective. This could come in the form of a single-payer model. Or by eschewing insurance pools outright by extending a government obligation to the health of the citizenry, commonly in the form of a universal healthcare system. Costs of the system would become a budgetary line-item so that the health department can focus its energy on care.
To be clear, the costs still have to be borne, but rather than fighting for reimbursement, it could be made into a form of mandatory spending, meaning that they are already authorized to be paid from the Treasury on an ongoing basis. For reference, the federal Medicare health insurance system (for people over 65) is already a mandatory spending obligation. So upgrading Medicare to universal old-people healthcare is not that far of a stretch.
Good luck with your endeavors! Always keep in mind that when debugging a complex problem, try isolating individual components and testing them individually. This can be as easy as swapping a web application with the Python SimpleHTTPServer to validate firewall and reverse proxy configuration.
Thank you for that detailed description. I see two things which are of concern: the first is the IPv6 network unreachable. The second is the lost IPv4 connection, as opposed to a rejection.
So staring in order, the machine on the external network that you’re running curl on, does it have a working IPv6 stack? As in, if you opened a web browser to https://test-ipv6.com/ , does it pass all or most tests? An immediate “network is unreachable” suggests that external machine doesn’t have IPv6 connectivity, which doesn’t help debug what’s going on with the services.
Also, you said that all services that aren’t on port 80 or 443 are working when viewed externally, but do you know if that was with IPv4 or IPv6? I use a browser extension called IPvFoo to display which protocol the page has loaded with, available for Chrome and Firefox. I would check that your services are working over IPv6 equally well as IPv4.
Now for the second issue. Since you said all services except those on port 80, 443 are reachable externally, that would mean the IP address – v4 or v6, whichever one worked – is reachable but specifically ports 80 and 443 did not.
On a local network, the norm (for properly administered networks) is for OS firewalls to REJECT unwanted traffic – I’m using all-caps simply because that’s what I learned from Linux IP tables. A REJECT means that the packet was discarded by the firewall, and then an ICMP notification is sent back to the original sender, indicating that the firewall didn’t want it and the sender can stop waiting for a reply.
For WANs, though, the norm is for an external-facing firewall to DROP unwanted traffic. The distinction is that DROPping is silent, whereas REJECT sends the notification. For port forwarding to work, both the firewall on your router and the firewall on your server must permit ports 80 and 443 through. It is a very rare network that blocks outbound ICMP messages from a LAN device to the Internet.
With all that said, I’m led to believe that your router’s firewall is not honoring your port-forward setting. Because if it did and your server’s firewall discarded the packet, it probably would have been a REJECT, not a silent drop. But curl showed your connection timed out, which usually means no notifications was received.
This is merely circumstantial, since there are some OS’s that will DROP even on the LAN, based on misguided and improper threat modeling. But you will want to focus on the router’s firewall, as one thing routers often do is intercept ports 80 and 443 for the router’s own web UI. Thus, you have to make sure there aren’t such hidden rules that preempt the port-forwarding table.
I’m still trying to understand exactly what you do have working. You have other services exposed by port numbers, and they’re accessible in the form <user>.ducksns.org:<port> with no problems there. And then you have Jellyfin, which you’re able to access at home using https://jellyfin.<user>.duckdns.org without problems.
But the moment you try accessing that same URL from an external network, it doesn’t work. Even if you use HTTP with no S, it still doesn’t connect. Do I understand that correctly?












{kind=link}
{kind=link}
{kind=link}
{kind=link}
A few months ago, my library gained a copy of Cybersecurity For Small Networks by Seth Enoka, published by No Starch Press in 2022. So I figured I’d have a look and see if it it included modern best-practices for networks.
It was alright, in that it’s a decent how-to guide for a novice to set up sensible, minimum network fortifications. But it only includes an overview of how those fortifications work, without going into the additional depth needed to fine-tune or optimize them for specific environments. So if the reader has zero experience with network security, it’s a worthwhile read. But if you’ve already been operating a network with defenses for a while, there’s not much to gain from this particular text.
Also, the author suggests that IPv6 should be disabled, which is a terrible idea. Modern best-practice is not to pretend IPv6 doesn’t exist, but to assure that firewalls and other defenses are configured to handle this traffic. There’s a vast difference between “administratively reject IPv6 traffic in/out of the WAN” and “disable IPv6 on all devices and pray no one ever connects an IPv6-enabled device”.
You might have a look at other books available from No Starch Press, though.