Attached: 4 images
As many of you know, I posted recently about my experiences and outlook on Kagi, the paid search engine. It's gotten some positive press recently, ironically right after I made my blog post about why I no longer liked or trusted it. This blog post was called "Why I Lost Faith In Kagi" and was a pretty simple quick collection of my thoughts that I primarily wrote so it'd be easier to find again later to link to people when discussing Kagi versus making it a fedi thread I couldn't search for easily later. Across the four social media platforms I linked this blog post on, I'd say it got a total of about 40 likes and few reblogs.
https://d-shoot.net/kagi.html
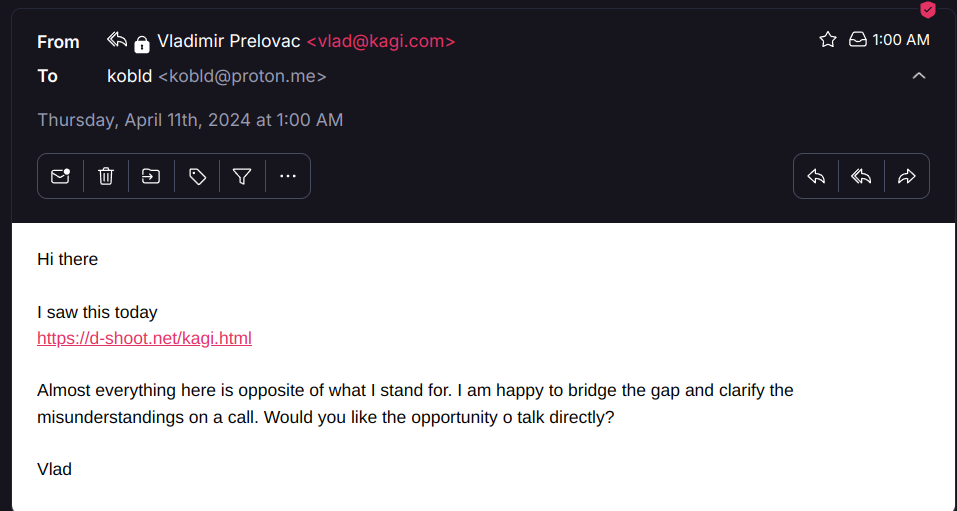
I say this because this morning I woke up to an email from Kagi's CEO, Vlad, who had seen the post and was upset about it. I have an email address listed on my blog (which is why I didn't bother removing it from these logs), which is what he sent his emails to. I am posting this entire email chain in this thread and will briefly post my thoughts about it, but I feel like it's something that needs to be seen. Please take note of the subject of the email as well (EDIT: It got cropped out sorry, the subject is "Fatih [sic] can not be lost"). Also, since the alt text would get extremely long with some of the transcripts, I've provided a text dump of the emails here for screen reader users and will offer a more abridged description in the alt text: https://d-shoot.net/files/kagiemails.txt
Ah man, same. Thought I’d give it a go after reading about if from Cory…
Honestly, for what I search for, DDG is sufficient, and it’s not gonna hassle me about subscriptions.
What I’d really like to find is something like a pihole for search, where you have your blocklist, cache of things you’ve searched already (your own mini search engine?), and then a fallback engine (DDG, bing, Google, whatever) for things it doesn’t already know.
I dunno. Search and AI botshit is everywhere, and it’s gonna keep getting worse. Self-hosting tools seems to be the only way to take control back.
I was trying and failing to do something like that. Basically, using ArchiveBox to download bookmarks, and then use recoll to index the webpages + PDFs + my own writing. Assumption was that I probably already bookmarked or had copies of what I wanted and just needed a quick way to find them. Was eventually going to import my browsing history as well. It ended up being more trouble than it was worth. (Too many bookmarks, not enough disk space, didn’t know what the best setting for ArchiveBox were, Archivebox has its own search and I wasn’t sure how that compared to recoll, unsure most efficient way to delete useless downloaded pages or curate them, etc.)
I do use uBlacklist and the Huge AI Blocklist subscription to try to clean up my search results. Not sure how effective they are over all though.
@shadow@V0ldek > What I’d really like to find is something like a pihole for search, where you have your blocklist, cache of things you’ve searched already (your own mini search engine?), and then a fallback engine (DDG, bing, Google, whatever) for things it doesn’t already know.
I think SearXNG sort of fulfills this, from what I’ve heard? It’s more or less a self-hosted search engine that can combine indexes from various other engines, and I presume that means you can set your own rules and filters and such. There are public instances as well.


I literally learnt about Kagi like a week ago from a Cory Doctorow’s post. I was like oh, cool, someone there to fight google.
I KNOW RIGHT
they just got THE BEST word of mouth
and then Vlad just …
So close!
We were right there!
And then Vlad had to do his impaling thing…
Ah man, same. Thought I’d give it a go after reading about if from Cory…
Honestly, for what I search for, DDG is sufficient, and it’s not gonna hassle me about subscriptions.
What I’d really like to find is something like a pihole for search, where you have your blocklist, cache of things you’ve searched already (your own mini search engine?), and then a fallback engine (DDG, bing, Google, whatever) for things it doesn’t already know.
I dunno. Search and AI botshit is everywhere, and it’s gonna keep getting worse. Self-hosting tools seems to be the only way to take control back.
I was trying and failing to do something like that. Basically, using ArchiveBox to download bookmarks, and then use recoll to index the webpages + PDFs + my own writing. Assumption was that I probably already bookmarked or had copies of what I wanted and just needed a quick way to find them. Was eventually going to import my browsing history as well. It ended up being more trouble than it was worth. (Too many bookmarks, not enough disk space, didn’t know what the best setting for ArchiveBox were, Archivebox has its own search and I wasn’t sure how that compared to recoll, unsure most efficient way to delete useless downloaded pages or curate them, etc.)
I do use uBlacklist and the Huge AI Blocklist subscription to try to clean up my search results. Not sure how effective they are over all though.
@shadow @V0ldek > What I’d really like to find is something like a pihole for search, where you have your blocklist, cache of things you’ve searched already (your own mini search engine?), and then a fallback engine (DDG, bing, Google, whatever) for things it doesn’t already know.
I think SearXNG sort of fulfills this, from what I’ve heard? It’s more or less a self-hosted search engine that can combine indexes from various other engines, and I presume that means you can set your own rules and filters and such. There are public instances as well.
The searxng public instances tend to be a bit shit.
They’re slow. Maybe only several seconds but that feels like an eternity in 2024.
They also frequently seem to be blocked by the services they’re scraping.
I will check out self hosting searxng
Isn’t the DDG guy an asshole as well though?
But you don’t pay him.
He’s not getting paid?
What I’m saying is that for Kagi you have to pay a direct subscription. DDG you can just use for free.
What I’m saying is that free things arent really free.
+5, insightful.
I found that while Doctorow post weird like an ad in the form of a post.