

Discussion of the current situation with the Blåhaj instances, and upcoming maintenance.
You must log in or register to comment.
I love that people in the comments here are like “have you tried” and “maybe we could”…as if I expected a server full of trans folks to NOT have a bunch of techie people on it :)
A few friendly recommendations that may help:
-
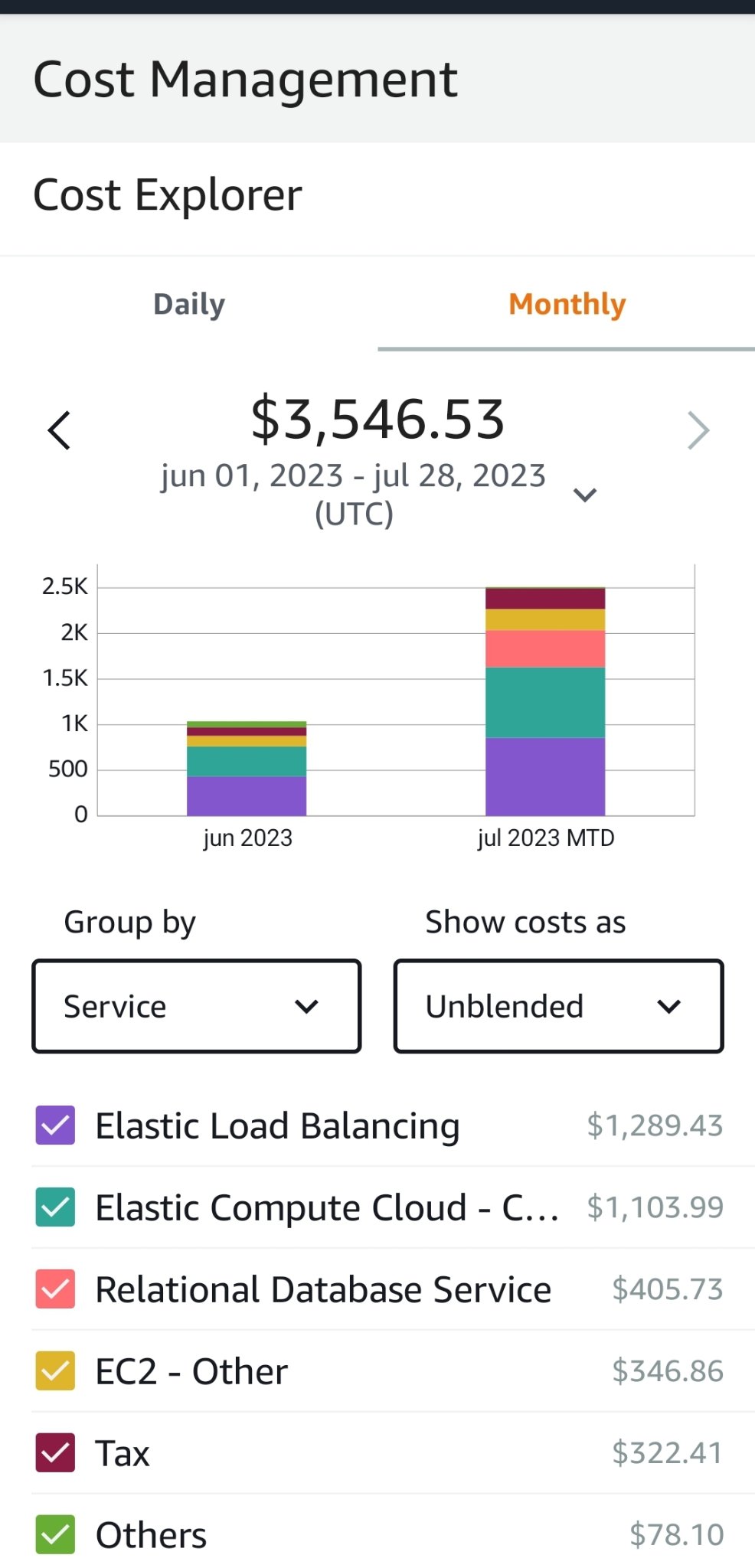
Remove the AWS load balancer. Your web application isn’t horizontally scaled so you don’t need that extra cost. Obviously you’ll still have to pay for bandwidth moving all those images but you remove the ELB hourly usage cost from the equation. If you’re using it for a reverse proxy, simply install a nginx container on the lemmy box. If really want a load balancer, you’ll save money by hosting haproxy on a regular server.
-
Get off Amazon RDS. You’ll save money by hosting your database on a regular server than using RDS. You’re moving from a fully managed solution to one you have to manage your own. This means managing your own backups and replication if you want HA failover.
-
Switch to object storage for pictrs. The cost is much lower.
However, you’re right that Amazon prices are high and you’ll likely find cheaper alternatives elsewhere.
I’m not sure I agree with moving from managed to unmanaged for RDS, unless you’re very familiar with databases and keeping them online, RDS (and other managed DB providers) are honestly one of the places I recommend spending more on.
The rest of your points are spot on though.
-
For just 50¢ a month you can can help save an instance like this one.
It seems like the images are playing a big role so perhaps having images being offloaded to another service (like catbox.moe) or converting images to WebP with a healthy amount of compression would help.
Basically decrease the amount of storage you folks are having to pay for.
Or auto delete pictures after a week or 2 and add a disclaimer about it to when pictures are being uploaded.
Maybe also a file size limit. Nothing over 10MB or whatever.
I hope this whole thing can be sorted out I dig this instance.
To be clear, we have the solution. This post was explaining future downtime and why it’s happening. We’re not going anywhere.
In trans nerds we trust :)
How much bandwidth does the instance use a day?
Over a terabyte
That’s crazy is there a breakdown of the bandwidth? Like is it federation, images or ddos using so much bandwidth?
I know you are looking/found a solution but if the main culprit is images would it be possible to offload it to a few servers? I feel like running multiple image server instances would be cheaper for bandwidth. Oracle cloud offers 10tb outbound a month for free per region/month on the free teir. Or is an unmetered host viable? From my understanding Lemmy is pretty light in terms of CPU/memory or does that fall apart at scale?
If you don’t mind and it’s not too much trouble would you be willing to share stuff like load average/disk use?
Edit I looked this over again. Not an endorsement for giving oracle or Larry Ellison money, they are awful. I was just was trying to say the free stuff is generous. You can use 40tb outbound without paying on the free resources. As always aggressive support for you Ada! Thanks for the transparency in your community!
It’s most images from lemmy. We’ve set up a caching server for pictrs, and that has got the bandwidth part under control.
Next step, get everything else off of AWS :)





